


1.5 Eingabe und Ausgabe 

Kommen wir nun zur Ein- und Ausgabe, einer der wichtigsten Funktionen eines Betriebssystems. Wir wollen diese dabei einmal prinzipiell und einmal konkret am Beispiel des Dateisystems behandeln.
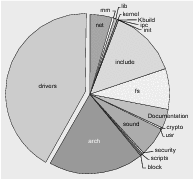
Abbildung 1.6 Der Anteil des Treibercodes an Kernel 2.6.10
An dieser Grafik kann man bereits sehen, wie wichtig das Ein-/Ausgabe-Subsystem des Kernels ist. Mittlerweile besteht fast die Hälfte des Kernel-Codes aus Quelldateien für verschiedenste Treiber. Im Folgenden wollen wir jedoch erst einmal erklären, was Sie sich unter dem Begriff »Treiber« vorstellen können.
1.5.1 Hardware und Treiber 
Damit ein Gerät angesprochen werden kann, muss man »seine Sprache sprechen«. Man muss genau definierte Daten in spezielle Hardware-Register oder auch Speicherstellen laden, um bestimmte Effekte zu erreichen. Daten werden hin und her übertragen, und am Ende druckt ein Drucker eine Textdatei oder man liest Daten von einer CD.
Schnittstelle
Damit man eine Schnittstelle zwischen den Benutzerprogrammen, die einen »CD-Brenner« unterstützen, und den eventuell von Hersteller zu Hersteller unterschiedlichen Hardware-Schnittstellen übersetzen kann, benötigt man Treiber.
Für die Anwenderprogramme werden die Geräte unter Unix als Dateien visualisiert. Als solche können sie natürlich von Programmen geöffnet und benutzt werden: Man sendet und empfängt Daten über Syscalls. Wie die zu sendenden Steuerdaten genau auszusehen haben, ist natürlich von Gerät zu Gerät unterschiedlich.
Auch das vom Treiber bereitgestellte Interface kann von Gerät zu Gerät unterschiedlich sein. Bei USB-Sticks oder CD-ROM-Laufwerken wird das Interface sicherlich so beschaffen sein, dass man die Geräte leicht in das Dateisystem integrieren und auf die entsprechenden Dateien und Verzeichnisse zugreifen kann. Bei einem Drucker jedoch möchte man dem Gerät die zu druckenden Daten schicken; das Interface wird also eine völlig andere Struktur haben. Auch kann ein Gerät durch verschiedene Treiber durchaus mehrere Schnittstellen anbieten: Eine Festplatte kann man sowohl über eine Art »Dateisystem-Interface« als auch direkt über das Interface des IDE-Treibers ansprechen.
Module
Die meisten Treiber sind unter Linux als Module realisiert. Solche Module werden zur Laufzeit in den Kernel eingebunden und stellen dort dann eine bestimmte Funktionalität zur Verfügung. Dazu sind aber einige Voraussetzungen nötig:
- Interface
- Der Kernel muss natürlich ein Interface anbieten, über das Module erst einmal geladen werden können. Einmal geladen, müssen die Module natürlich auch irgendwie in den Kernel integriert werden können.
- Sicherheit
- Lädt man externe Komponenten in den Kernel, ist dies natürlich immer ein Sicherheitsrisiko in doppelter Hinsicht.
- Einerseits könnten schlecht programmierte Treiber das ganze System zum Absturz bringen, und andererseits könnten Hacker durch spezielle Module versuchen, den Kernel zu manipulieren.
- Gerätemanagement
- Ein Modul beziehungsweise ein Treiber muss beim Laden sagen können: Ich bin jetzt für dieses oder jenes Gerät verantwortlich. Vielleicht muss mancher Treiber auch erst erkennen, ob und wie viele vom Treiber unterstützte Geräte angeschlossen sind.
Aber was wäre die Alternative zu Treibern in Modulform? Treiber müssen teilweise privilegierte Befehle zur Kommunikation mit den zu steuernden Geräten nutzen, daher müssen sie zumindest zum großen Teil im Kernelmode ablaufen. Und wenn man sie nicht zur Laufzeit in den Kernel laden kann, müssten sie schon von Anfang an in den Kernel-Code integriert sein.
Modulare vs. statische Integration
Würde man jedoch alle verfügbaren Treiber »ab Werk« direkt in den Kernel kompilieren, wäre der Kernel sehr groß und damit langsam sowie speicherfressend. Daher sind die meisten Distributionen dazu übergegangen, ihre Kernel mit in Modulform kompilierten Treibern auszuliefern. Der Benutzer kann dann alle entsprechenden Module laden, die er braucht – beziehungsweise das System erledigt diese Aufgabe automatisch für ihn. <Wie man selbst Module lädt und das System so konfiguriert, dass es dies automatisch tut, erfahren Sie im Kapitel zur Systemadministration.>
Zeichenorientierte Treiber
Die Treiber müssen aber irgendwie ins System eingebunden werden, mit anderen Worten: Man benötigt eine einigermaßen uniforme Schnittstelle. Aber kann man zum Beispiel eine USB-Webcam und eine Festplatte in ein einheitliches und trotzdem konsistentes Muster bringen? Nun ja, Unix hat es zumindest versucht und unterscheidet zwischen zeichenorientierten und blockorientierten Geräten und klassifiziert damit auch die Treiber entsprechend. Der Unterschied ist dabei relativ simpel und doch signifikant:
Ein zeichenorientiertes Gerät sendet und empfängt Daten direkt von Benutzerprogrammen.
Keine Pufferung
Der Name dieser Geräte kommt von der Eigenschaft bestimmter serieller Schnittstellen, nur jeweils ein Zeichen während einer Zeiteinheit übertragen zu können. Diese Zeichen konnten nun aber direkt – also im Besonderen ohne Pufferung – gesendet und empfangen werden. Eine weitere wichtige Eigenschaft ist die, dass auf Daten im Allgemeinen nicht wahlfrei zugegriffen werden kann. Man muss eben mit den Zeichen vorlieb nehmen, die gerade an der Schnittstelle anliegen.
Blockorientierte Treiber
Im Gegensatz dazu stehen blockorientierte Geräte, bei denen meist ganze Datenblöcke auf einmal übertragen werden.
Der klassische Vertreter dieser Gattung ist die Festplatte, bei der auch nur eine blockweise Übertragung der Daten sinnvoll ist. Der Lesevorgang bestimmter Daten gliedert sich nämlich in diese Schritte:
| 1. | Aus der Blocknummer – einer Art Adresse – wird die physikalische Position der Daten ermittelt. |
| 2. | Der Lesekopf der Platte bewegt sich zur entsprechenden Stelle. |
| 3. | Im Mittel muss nun eine halbe Umdrehung gewartet werden, bis die Daten am Lesekopf anliegen. |
| 4. | Der Lesekopf liest die Daten. |
Mehrere Daten auf einmal
Die meiste Zeit braucht nun aber die Positionierung des Lesekopfes, denn wenn die Daten einmal am Lesekopf anliegen, geht das Einlesen sehr schnell. Mit anderen Worten: Es ist für eine Festplatte praktisch, mit einem Zugriff gleich mehrere Daten – zum Beispiel 512 Bytes – zu lesen, da hier die zeitaufwendige Positionierung eben nur einmal statt 512-mal erfolgen muss.
Blockorientierte Geräte haben die gemeinsame Eigenschaft, dass die übertragenen Daten gepuffert werden.
Außerdem kann auf die gespeicherten Blöcke wahlfrei, also in beliebiger Reihenfolge zugegriffen werden.
Im Besonderen können Datenblöcke mehrfach gelesen werden.
Bei einer Festplatte hat dies nun gewisse Vorteile wie auch Nachteile: Während des Arbeitens bringen zum Beispiel Schreib- und Lesepuffer eine große Performance. Wenn ein Benutzer die ersten Bytes einer Datei lesen möchte, kann man schließlich auch gleich ein Readahead machen und die darauf folgenden Daten schon mal vorsichtshalber im Hauptspeicher puffern. Dort können sie dann ohne Zeitverzug abgerufen werden, wenn ein Programm – was ziemlich wahrscheinlich ist – in der Datei weiterlesen will. Will es das nicht, gibt man den Puffer eben nach einiger Zeit wieder frei.
Schreibpuffer
Beim Schreibpuffer sieht das Ganze ähnlich aus: Um performanter zu arbeiten, werden Schreibzugriffe in der Regel nicht sofort, sondern in Zeiten geringer Systemauslastung ausgeführt. Wenn ein System nun aber nicht ordnungsgemäß heruntergefahren wird, kann es zu Datenverlusten bei eigentlich schon getätigten Schreibzugriffen kommen. Wenn diese nämlich ausgeführt und in den Puffer, aber eben noch nicht auf die Platte geschrieben wurden, sind die Daten weg.
Ein interessantes Beispiel für die Semantik dieser Treiber ist eine USB-Festplatte. Es handelt sich bei diesem Gerät schließlich um eine blockorientierte Festplatte, die über einen seriellen, »zeichenorientierten« Anschluss mit dem System verbunden ist. Sinnvollerweise wird die Funktionalität der Festplatte über einen blockorientierten Treiber angesprochen, der aber intern wiederum über den USB-Anschluss und damit über einen zeichenorientierten Treiber die einzelnen Daten an die Platte schickt beziehungsweise von ihr liest.
Mit anderen Worten: Der wahlfreie Zugriff auf die Datenblöcke der Festplatte wird über die am seriellen USB-Anschluss übertragenen Daten erledigt. Der Blocktreiber nutzt also eine bestimmte Sprache zur Ansteuerung des Geräts, und der zeichenorientierte USB-Treiber überträgt dann die »Worte« dieser Sprache sowie eventuell zu lesende oder zu schreibende Daten.
1.5.2 Interaktion mit Geräten
Da wir im letzten Abschnitt grob die unterschiedlichen Treiber behandelt haben, wollen wir im Folgenden den Zugriff auf diese Treiber aus dem Userspace heraus betrachten und dabei den internen Aufbau der Treiber etwas näher analysieren.
Gehen wir also wieder ein paar Schritte zurück, und führen wir uns vor Augen, dass die Geräte unter Linux allesamt als Dateien unterhalb des /dev-Verzeichnisses repräsentiert sind. Die Frage ist nun, wie man diese Geräte und Ressourcen nutzen kann und wie der Treiber diese Nutzung unterstützt.
Den passenden Treiber finden
Major- und Minor-Nummern
Früher war die Sache relativ einfach: Jeder speziellen Gerätedatei unterhalb des /dev-Verzeichnisses war eine sogenannte Major- und eine Minor-Nummer zugeordnet. Anhand der Major-Nummer konnte festgestellt werden, welcher Treiber für diese spezielle Gerätedatei zuständig war. Die Minor-Nummer war schließlich für den Treiber selbst eine Hilfe, um festzustellen, welches Gerät nun anzusprechen war – schließlich war es gut möglich, dass in einem System zwei baugleiche Komponenten wie beispielsweise Festplatten verwendet wurden, die zwar vom selben Treiber bedient, aber trotzdem unterschieden werden mussten.
Später dachte man sich, dass man die Geräte doch nicht über statische Nummern identifizieren, sondern stattdessen eine namensbasierte Identifizierung verwenden sollte – das devfs war geboren. Der Treiber musste nun beim Laden nicht mehr angeben, welche Major-Nummer er bediente, sondern er registrierte sozusagen den »Namen« des Geräts.
Das konnte dann im Modulcode recht einfach geschehen:
#include <linux/devfs_fs_kernel.h>
static int __init treiber_init(void)
{
// Ist dieses Gerät schon registriert?
if(register_chrdev(4, "Treibername", &fops) == 0)
{
// Können wir uns registrieren?
if(devfs_mk_cdev( MKDEV(4,64),
S_IFCHR | S_IRUGO | S_IWUGO, "vc/ttyS%d", 0 ))
// Wenn nein, dann Fehlermeldung ausgeben
printk( KERN_ERR "Integration "
"fehlgeschlagen. \n");
}
}Listing 1.23 So wurde beim devfs ein Gerät registriert
Ein Irrweg
In diesem Beispiel wurde das zeichenorientierte Gerät »ttyS0« über die Funktion devfs_mk_cdev <Für blockorientierte Geräte gibt es einen entsprechenden anderen Befehl, der auch mit richtigen Parametern – S_IFCHR steht im Beispiel für zeichenorientierte Geräte – aufgerufen werden muss.> im Verzeichnis »vc« angelegt. Das devfs hat jedoch nicht zu unterschätzende Nachteile, daher wird es vom 2.6er Linux zwar noch unterstützt, ist aber als »deprecated« und damit als nicht mehr unterstützt gekennzeichnet. Die Nachteile sind dabei unter anderem:
- Die Implementierung des devfs ist sehr umfangreich und damit schlecht skalierbar, außerdem wird der Code
- als nicht besonders gut angesehen.
- Die Gerätedateien haben im devfs neue Namen, die nicht mehr standardkonform sind.
- Nicht alle Treiber funktionieren für das devfs.
- Die Methode, die Zugriffsrechte für eine von einem Treiber erstellte Datei zu setzen, ist sehr umständlich.
Also musste man wieder eine neue Lösung finden und kehrte schließlich wieder zu einer Identifizierung über Nummern zurück.
Jedoch warf man eine der Altlasten von Unix – die Beschränkung auf jeweils 8 Bit für die Major- und Minor-Nummer – über Bord und führte mit Kernel 2.6 die 32 Bit lange Gerätenummer ein. Natürlich kann man, wie im Beispiel gesehen, von den bekannten Major- und Minor-Nummern mittels des »MKDEV(major,minor)«-Makros diese Nummern auf den 32-Bit-Wert der Gerätenummer abbilden.
Also musste wieder etwas Neues her. Im Zuge der Weiterentwicklung des Powermanagements kam den Entwicklern eine andere Art der Geräteverwaltung in den Sinn: die Verwaltung in Form eines Baumes, der die Zusammenhänge des Prozessors mit den Controller-Bausteinen verschiedener Bussysteme und schließlich mit der über diese Bussysteme angebundenen Peripherie abbildet. Das heißt nichts anderes, als dass ein Treiber wissen muss, ob sein Gerät zum Beispiel am PCI- oder USB-Bus hängt – für das Powermanagement ist das insofern wichtig, als zum Beispiel der PCI-Bus erst nach der Deaktivierung des letzten PCI-Geräts heruntergefahren werden sollte.
Das sysfs
Visualisieren kann man sich diese Struktur über das sysfs, ein virtuelles, also nicht irgendwo auf einem Medium abgelegtes, sondern vielmehr dynamisch generiertes Dateisystem. Dieses spezielle Dateisystem muss erst gemountet werden, bevor man die zahlreichen Daten auslesen kann:
# mount -t sysfs sysfs /sys # ls /sys/* /sys/block: fd0 hdb hdd ram1 ram11 ram13 ram15 ram3 ... hda hdc ram0 ram10 ram12 ram14 ram2 ram4 ... /sys/bus: ide pci platform pnp usb /sys/class: graphics input mem misc net nvidia pci_bus ... /sys/devices: pci0000:00 platform pnp0 pnp1 system /sys/firmware: acpi /sys/module: 8139too commoncap ide_disk nvidia ... af_packet dm_mod ide_floppy ppp_generic ... agpgart ext3 ide_generic pppoe ... ... ... ... ... ... /sys/power: state
Listing 1.24 Das sysfs mounten und anzeigen
An diesem Beispiel kann man schon erkennen, dass das sysfs alle wichtigen Informationen über geladene Module, Geräteklassen und Bussysteme enthält. Ein Gerät kann im sysfs also durchaus mehrfach auftauchen, eine Netzwerkkarte würde zum Beispiel unterhalb des /sys/pci-Verzeichnisses und unterhalb der Geräteklasse /sys/net erscheinen.
Intelligenterweise muss man sich als Treiberprogrammierer in den seltensten Fällen mit dem Eintrag seines Geräts ins sysfs beschäftigen, Ausnahmefälle wären aber beispielsweise eine neue Geräteklasse oder besondere Powermanagement-Funktionen.
Einen besonders einfachen Fall wollen wir hier noch einmal kurz zeigen: Ein zeichenorientiertes Gerät mit der Major-Nummer 62 soll ins System integriert werden.
#include <linux/fs.h>
static struct file_operations fops;
int init_driver(void)
{
if(register_chrdev(62, "NeuerTreiber", &fops) == 0)
// Treiber erfolgreich angemeldet
return 0;
// Ansonsten: Anmeldung fehlgeschlagen
return –1;
}Listing 1.25 Ein Gerät registrieren
Hier geben wir wieder nur eine Major-Nummer an, denn aus dieser kann der Kernel eine gültige Gerätenummer generieren.
Ist diese Major-Nummer schon vergeben, wird das Registrieren des Geräts unweigerlich fehlschlagen. Jedoch kann man sich auch über die spezielle Major-Nummer 0 einfach eine beliebige freie Nummer zuweisen lassen. Mit der Zeichenkette »NeuerTreiber« identifiziert sich der Treiber im System, taucht unter dieser Bezeichnung im sysfs auf und kann sich mit dieser Kennung natürlich auch wieder abmelden.
Auf das Gerät zugreifen
I/O-Syscalls
Geräte sind also Dateien, auf die man im Wesentlichen mit den üblichen Syscalls <Bei der Kommunikation mit Gerätedateien werden die C-Funktionen fopen(), fprintf() usw. in der Regel nicht verwendet. Zwar greifen diese Funktionen intern auch auf die Syscalls zurück, allerdings wird standardmäßig gepufferte Ein-/Ausgabe benutzt, was im Regelfall für die Kommunikation mit Geräten nicht ideal ist.> zur Dateibearbeitung zugreifen wird:
- open()
- write()
- read()
- close()
- seek()
- ioctl()
Diese Schnittstellen müssen nun natürlich vom Treiber als Callbacks bereitgestellt werden. Callbacks sind Funktionen, die genau dann aufgerufen werden, wenn ein entsprechender Event – in diesem Fall die Benutzung des entsprechenden Syscalls auf eine Gerätedatei – auftritt.
Wenn eine Applikation also mittels open() eine Gerätedatei öffnet, stellt der Kernel den zugehörigen Treiber anhand der Major/Minor- beziehungsweise der Gerätenummer fest. Danach erstellt der Kernel im Prozesskontext eine Datenstruktur vom Typ struct file, in der sämtliche Optionen des Dateizugriffs wie die Einstellung für blockierende oder nichtblockierende Ein-/Ausgabe oder natürlich auch die Assoziation zur geöffneten Datei gespeichert werden.
Callbacks
Als Nächstes wird beim Treiber der in der file_operations-Struktur vermerkte Callback für den open()-Syscall ausgerufen, der unter anderem eine Referenz dieser file-Struktur übergeben bekommt.
Anhand dieser wird auch bei allen anderen Callbacks die Treiberinstanz referenziert.
Eine Treiberinstanz ist notwendig, da ein Treiber die Möglichkeit benötigt, sitzungsspezifische Daten zu speichern.
Solche Daten könnten zum Beispiel ein Zeiger sein, der die aktuelle Position in einem Datenstrom anzeigt. Und dieser muss natürlich pro geöffneter Datei eindeutig sein, selbst wenn ein Prozess ein Gerät mehrfach geöffnet hat.
1.5.3 Ein-/Ausgabe für Benutzerprogramme
Für Benutzerprogramme spiegelt sich dieser Kontext im Deskriptor wider, der nach einem erfolgreichen open() als Rückgabewert an das aufrufende Programm übergeben wird:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
// Ein Deskriptor ist nur eine Identifikationsnummer
int fd;
char text[256];
// Die Datei "test.c" lesend öffnen und den zurück-
// gegebenen Deskriptor der Variable fd zuweisen
fd = open( "test.c", O_RDONLY );
// Aus der Datei unter Angabe des Deskriptors lesen
read( fd, text, 256 );
// "text" verarbeiten
// Danach die Datei schließen
close( fd );
return 0;
}Listing 1.26 Einen Deskriptor benutzen
ioctl()
Ein wichtiger Syscall im Zusammenhang mit der Ein-/Ausgabe auf Gerätedateien ist ioctl() (»I/O-Control«).
Über diesen Syscall können alle Funktionalitäten abgebildet werden, die nicht in das normale standardisierte Interface eingebaut werden können.
1.5.4 Das Dateisystem
Ein besonderer Fall der Ein-/Ausgabe ist natürlich das Dateisystem, das wir im Folgenden daher auch näher behandeln wollen. Eigentlich müssen wir dabei zwischen »Dateisystem« und »Dateisystem« unterscheiden, da Unix mehrere Schichten für die Interaktion mit Dateien benutzt.
Der VFS-Layer
Die oberste Schicht des Dateisystems ist der sogenannte VFS-Layer (engl. »virtual filesystem«).
Das virtuelle Dateisystem ist eine Schnittstelle, die von den physikalischen Dateisystemen die grundlegenden Funktionen beim Umgang mit Dateien abstrahiert:
- open() und close()
Treiberarbeit
Wie Sie schon bei dem Umgang mit Treibern und Geräten gesehen haben, ist eine Möglichkeit zum Öffnen und Schließen von Dateien essenziell. Mit dieser Architektur setzt das VFS jedoch eine zustandsbasierte Funktionsweise des Dateisystems voraus. Beim Netzwerkdateisystem NFS ist dies aber nicht gegeben: Dort gibt es keine open()-
- oder close()-Aufrufe, stattdessen müssen bei jedem lesenden oder schreibenden Zugriff der Dateiname sowie die Position innerhalb der Datei angegeben werden. Damit ein NFS-Dateisystem von einem entfernten Server nun in das VFS integriert werden kann, muss der lokale Treiber sich den jeweiligen Zustand einer geöffneten Datei merken und bei jedem Zugriff in die Anfragen für den NFS-Server übersetzen.
- read() und write()
- Hat man eine Datei einmal geöffnet, kann man über einen Deskriptor Daten von der aktuellen Position in der Datei lesen oder schreiben. Nachdem das VFS bereits beim open() festgestellt hat, zu welchem physikalischen Dateisystem ein Zugriff gehört, wird jeder read()- oder write()-Aufruf wieder direkt zum Treiber für das entsprechende Dateisystem weitergeleitet.
- create() und unlink()
- Das VFS abstrahiert natürlich auch die Erstellung und das Löschen von Dateien. Die Erstellung wird dabei allerdings über den open()-Syscall abgewickelt.
- readdir()
- Genauso muss natürlich auch ein Verzeichnis gelesen werden können. Schließlich ist die Art und Weise, wie ein Dateisystem auf einem Medium abgelegt ist, ebenfalls treiberspezifisch.
Der Benutzer beziehungsweise seine Programme greifen nun über solche uniformen Schnittstellen des VFS auf die Funktionen und Daten des physikalischen Dateisystems zu. Der Treiber des Dateisystems muss also entsprechende Schnittstellen anbieten, damit er in das VFS integriert werden kann.
Mehr Interna zu Dateisystemen finden Sie in Kapitel 26.
Mounting
Das Einbinden eines Dateisystems in das VFS nennt man Mounting. Eingebunden werden die Dateisysteme schließlich unterhalb von bestimmten Verzeichnissen, den sogenannten Mountpoints. Definiert wird das Ganze in einer Datei im Userspace, der /etc/fstab:
# Partitionen /dev/hda1 / ext3 errors=remount-ro 0 1 /dev/hda3 /home reiserfs defaults 0 0 /dev/hda4 none swap sw 0 0 # Wechselspeicher /dev/fd0 /mnt/floppy auto user,noauto 0 0 /dev/hdc /mnt/dvd iso9660 ro,user,noauto 0 0 /dev/hdd /mnt/cdburn auto ro,user,noauto 0 0 # virtuelle Dateisysteme proc /proc proc defaults 0 0
Listing 1.27 Eine /etc/fstab
Interessant sind für uns im Moment dabei vor allem die ersten beiden Spalten dieser Tabelle: Dort werden das Device sowie eben der Mountpoint angegeben, wo das auf dem Gerät befindliche Dateisystem eingehängt werden wird.
Option beim Booten
Besonders interessant ist an dieser Stelle das Root-Dateisystem »/«. Wie gesagt befindet sich die /etc/fstab irgendwo auf dem Dateisystem, auf das man nur zugreifen kann, wenn man zumindest das Root-Dateisystem schon gemountet hat. Man hat also das klassische Henne-Ei-Problem, das nur gelöst werden kann, wenn der Kernel das Root-Dateisystem als Option beim Booten übergeben bekommt.
So kennen die Bootmanager lilo und grub eine Option »root«, mit der man dem zu bootenden Kernel sein Root-Dateisystem übergibt. Von diesem kann er dann die fstab lesen und alle weiteren Dateisysteme einbinden.

 Jetzt bestellen
Jetzt bestellen





