


4.2 Der Stream-Editor sed 

In diesem Unterkapitel soll es nicht um die ehemalige DDR-Partei, sondern um einen mächtigen Editor gehen, der zum Standardumfang eines jeden Unix-Systems gehört.
sed ist kein herkömmlicher Editor, wie man ihn etwa von einer grafischen Oberfläche, ncurses-basiert oder dem vi ähnelnd kennt. sed verfügt über keinerlei Oberfläche, nicht einmal über die Möglichkeit, während der Laufzeit interaktiv eine Editierung vorzunehmen.
Der Nutzen von sed ist auch nicht völlig mit dem eines »normalen« Editors gleichzusetzen. Die Aufgabe von sed ist die automatische Manipulation von Text-Streams. Ein Text-Stream ist dabei nichts anderes als ein »Strom von Zeichen«. Dieser kann sowohl direkt aus einer Datei, aber auch aus einer Pipe kommen.
Dabei liest sed den Stream zeilenweise ein und manipuliert Zeile für Zeile nach dem Muster, das ihm vom Anwender vorgegebenen wurde.
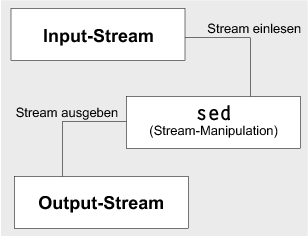
Abbildung 4.1 Die Arbeitsweise von sed
4.2.1 Was bringt mir sed? 
sed ist oftmals dann von hohem Nutzen, wenn es darum geht, ständig wiederkehrende Daten anzupassen beziehungsweise zu manipulieren. Dies ist besonders in Shellskripten und in der Systemadministration oft der Fall. sed nimmt daher neben awk eine dominante Rolle in der Stream-Manipulation ein. Im Gegensatz zu awk bietet sed keine so guten Möglichkeiten in der Programmierung, dafür ist es oftmals einfacher und schneller einsetzbar, was die bloße Manipulation von Streams anbelangt.
Diese Manipulation ist (ähnlich awk) besonders durch die Möglichkeit, reguläre Ausdrücke zu verwenden, äußerst einfach und dynamisch zu handhaben.
4.2.2 Erste Schritte mit sed
Der Aufruf von sed erfolgt durch Angabe einer Manipulationsanweisung (entweder direkt in der Kommandozeile oder durch eine Skript-Datei, die diese Anweisung(en) enthält).
Dazu übergibt man entweder eine Datei, die als Eingabequelle dienen soll, oder tut eben dies nicht, worauf sed von der Standardeingabe liest.
sed [Option] [Skript] [Eingabedatei]
Listing 4.3 sed aufrufen
Sofern sed ohne Eingabedatei betrieben wird, muss das Programm manuell durch die Tastenkombination Strg+D beendet werden. Auf dem Bildschirm erscheint dann die Ausgabe ^D.
Zunächst einmal gibt sed standardmäßig alle Zeilen nach der Bearbeitung aus. Um dies zu veranschaulichen, verwenden wir einen sehr einfachen sed-Aufruf. Dabei wird die Anweisung 'p' verwendet. Diese besagt in diesem Fall nichts weiter, als dass alle Zeilen ausgegeben werden sollen. Doch wie Sie sehen ...
user$ sed 'p'
Hallo, Sed! # dies ist die manuelle Eingabe
Hallo, Sed! # dies bewirkt 'p'
Hallo, Sed! # dies ist die standardmäßige Ausgabe
^D # sed wird durch Strg+D beendetListing 4.4 sed 'p'
... gibt sed unsere eingegebene Zeile zweimal aus. Die erste Ausgabe kam durch den Befehl »'p'«, die zweite durch die standardmäßige Ausgabe jeder manipulierten Zeile zustande. Um dieses, manchmal unerwünschte Feature zu deaktivieren, muss die Option -n verwendet werden:
user$ sed -n 'p'
Hallo, Sed!
Hallo, Sed!
^DListing 4.5 sed -n 'p'
sed mit Eingabedatei
Verwendet man nun eine Datei als Stream-Quelle, muss diese nur zusätzlich beim Aufruf angegeben werden. Da Sie bereits den Befehl 'p' kennen, werden Sie vielleicht schon auf die Idee gekommen sein, sed einmal als cat-Ersatz zu betrachten. cat gibt den Inhalt einer Datei auf dem Bildschirm aus. sed tut dies bei alleiniger Verwendung des 'p'-Befehls ebenfalls.
user$ sed -n 'p' /etc/passwd
root:x:0:0::/root:/bin/zsh
bin:x:1:1:bin:/bin:
daemon:x:2:2:daemon:/sbin:
adm:x:3:4:adm:/var/log:
lp:x:4:7:lp:/var/spool/lpd:
sync:x:5:0:sync:/sbin:/bin/sync
...Listing 4.6 sed mit Eingabedatei
4.2.3 sed-Befehle
Beschäftigen wir uns nun mit den Befehlen, die uns in sed zur Verfügung stehen. Mit dem ersten Befehl »p« sind Sie bereits in Kontakt gekommen. Dieser Befehl gibt die Zeilen aus.
Doch wie wendet man nun einen regulären Ausdruck auf solch einen Befehl an? Die Antwort ist recht simpel: Man schreibt den regulären Ausdruck in zwei Slashes und den Befehl (je nach Befehl) vor oder hinter die Slashes. Alles zusammen schreibt man der Einfachheit halber in Hochkommas, damit die Metazeichen nicht anderweitig von der Shell interpretiert werden – etwa so:
$ sed -n '/[Ff]/p' StandorteDieser Ausdruck würde nun alle Zeilen, in denen ein großes oder kleines »f« enthalten ist, herausfiltern und diese anschließend auf der Standardausgabe ausgeben (p).
Hold- und Patternspace
Zur internen Funktionsweise von sed ist noch zu sagen, dass das Programm mit zwei Puffern arbeitet, in denen die Zeilen gespeichert werden. Der erste Puffer ist der Patternspace. In diesen wird ein Pattern geladen, nachdem es einem Muster entsprach. Der zweite Puffer ist der Holdspace. Nach der Bearbeitung einer Zeile wird diese vom Pattern- in den Holdspace kopiert. Hier ein Beispiel:
Der Befehl »x« tauscht den Inhalt des Patterns mit dem des Holdspace. Dies geschieht jedes Mal dann, wenn eine Zeile ein großes »F« enthält, da wir dies als Muster angegeben haben.
user$ sed '/F/x' Standorte
Augsburg
Bremen
Aschersleben
Bernburg
Berlin
Halle
Essen
Friedrichshafen
Kehlen
...Listing 4.7 Austausch von Hold- und Patternspace
Wie Sie sehen, folgt nach Bremen eine Leerzeile. Dort ist der Holdspace noch leer gewesen. Da dieser aber mit dem Patternspace (der »Friedrichshafen« enthielt) vertauscht wurde, wurde eine leere Zeile ausgegeben. Nachdem die Leerzeile ausgegeben wurde, befindet sich nun also »Friedrichshafen« im Holdspace. Später wird »Friedrichshafen« ausgegeben, obwohl »Furtwangen« im Patternspace enthalten war. Dies liegt auch wieder daran, dass durch den »x«-Befehl der Pattern- und der Holdspace vertauscht wurden. Doch es gibt noch einige weitere sed-Befehle, hier sind die wichtigsten:
| Befehl | Auswirkung |
|
/ausdruck/= |
Gibt die Nummern der gefundenen Zeilen aus. |
|
/ausdruck/a\string |
Hängt »string« hinter die Zeile an, in der »ausdruck« gefunden wird. (append) |
|
b label |
Springt zum Punkt »label« im sed-Skript. Falls »label« nicht existiert, wird zum Skriptende gesprungen. |
|
/ausdruck/c\string |
Ersetzt die gefundenen Zeilen durch »string«. (change) |
|
/ausdruck/d |
Löscht die Zeilen, in denen »ausdruck« gefunden wird. (delete) |
|
/ausdruck/D |
Löscht bis zum ersten eingebundenen Zeilenumbruch (\n) in »ausdruck«. |
|
/ausdruck/i\string |
Setzt »string« vor der Zeile ein, in der »ausdruck« gefunden wird. (insert) |
|
/ausdruck/p |
Gibt die gefundenen Zeilen aus. (print) |
|
/ausdruck/q |
Beendet sed, nachdem »ausdruck« gefunden wurde. (quit) |
|
/ausdruck/r datei |
Hängt hinter »ausdruck« den Inhalt der Datei »datei« an. (read from file) |
|
s/ausdruck/string/ |
Ersetzt »ausdruck« durch »string«. Ein Beispiel zu diesem Befehl folgt weiter unten. |
|
t label |
Falls seit dem letzten Lesen einer Zeile oder der Ausführung eines t-Befehls eine Substitution (s-Befehl) stattfand, wird zu »label« gesprungen. Lässt man »label« weg, wird zum Skriptende gesprungen. |
|
/ausdruck/w datei |
Schreibt den Patternspace in die Datei »datei«. Ein Beispiel zu diesem Befehl folgt weiter unten. |
|
/ausdruck/x |
Tauscht den Inhalt des Haltepuffers mit dem des Eingabepuffers. Eine Beispielanwendung dieses Befehls finden Sie in dem Listing, das der Tabelle voranging. |
|
y/string1/string2/ |
Vertauscht alle Zeichen, die in »string1« vorkommen, mit denen, die in »string2« angegeben sind, wobei die Positionen der Zeichen entscheidend sind: Das zweite Zeichen in »string1« wird durch das zweite in »string2« ersetzt usw. Ein Beispiel zu diesem Befehl folgt weiter unten. |
Es folgen nun einige Listings zur exemplarischen Anwendung von sed.
Zunächst soll der Befehl w angewandt werden, der die gefundenen Ausdrücke in eine Datei schreibt. Um alle anderen Ausdrücke zu unterdrücken, wird die Option -n verwendet.
Es sollen dabei alle Zeilen, in denen ein »F« vorkommt, in die Datei out.log geschrieben werden.
$ sed -n '/F/w out.log' Standorte $ cat out.log Friedrichshafen Furtwangen
Listing 4.8 w-Befehl
s-Befehl
Aber auch die Substitution von Ausdrücken ist in sed kein Problem. Mit dem Befehl s kann ohne Weiteres ein Ausdruck durch einen String ersetzt werden. Im Folgenden sollen alle »n«-Zeichen durch den String »123456« ersetzt werden.
$ sed 's/n/123456/' Standorte
Augsburg
Breme123456
Friedrichshafe123456
Ascherslebe123456
Ber123456burg
Berli123456
Halle
Esse123456
Furtwa123456gen
Kehle123456
Krumbach
Os123456abrueck
Kempte123456Listing 4.9 s-Befehl
y-Befehl
Eine ähnliche Funktionalität bietet der y-Befehl. Dieser Befehl ersetzt keine ganzen Strings, sondern einzelne Zeichen. Er sucht zudem nicht nach Ausdrücken, sondern explizit nach den ihm angegebenen Zeichen. Dem Befehl werden zwei Zeichenketten übergeben. In der ersten steht an jeder Stelle ein Zeichen, das im zweiten String an derselben Stelle ein Ersatzzeichen findet. Daher müssen beide Strings gleich lang sein. Im nächsten Listing soll »a« durch ein »i«, »b« durch ein »j« ... und »h« durch ein »p« ersetzt werden.
$ sed 'y/abcdefgh/ijklmnop/' Standorte
Auosjuro
Brmmmn
Frimlrikpspinmn
Askpmrslmjmn
Bmrnjuro
Bmrlin
Hillm
Essmn
Furtwinomn
Kmplmn
Krumjikp
Osnijrumkk
KmmptmnListing 4.10 y-Befehl
4.2.4 Nach Zeilen filtern
Ein weiteres Feature von sed ist die Möglichkeit, nach bestimmten Zeilen zu filtern. Dabei kann entweder explizit eine Zeile oder ein ganzer Zeilenbereich angegeben werden.
Gegeben sei die Datei myfile mit dem folgenden Inhalt:
$ cat myfile
Zeile1
Zeile2
Zeile3
Zeile4
Zeile5
Zeile6Listing 4.11 myfile
Einzelzeilen
Eine Einzelzeile kann durch Angabe der Zeilennummer in Verbindung mit dem p-Befehl herausgefiltert werden. Durch die Option -e können noch weitere Einzelzeilen in einem einzelnen Aufruf von sed gefiltert werden.
$ sed -n '2p' myfile Zeile2 $ sed -n -e '1p' -e '2p' myfile Zeile1 Zeile2
Listing 4.12 Einzelzeilen filtern
Zeilenbereiche
Um nun nach Zeilenbereichen zu filtern, gibt man die beiden Zeilennummern, die diesen Bereich begrenzen, getrennt durch ein Kommata an.
$ sed -n '2,5p' myfile
Zeile2
Zeile3
Zeile4
Zeile5Listing 4.13 Zeilenbereiche
$
Das Dollarzeichen steht dabei symbolisch für das Zeilenende:
$ sed -n '3,$p' myfile
Zeile3
Zeile4
Zeile5
Zeile6
$ sed -n '$p' myfile
Zeile6Listing 4.14 $
4.2.5 Wiederholungen in regulären Ausdrücken
Kommen wir nun zu einem weiteren Feature in Bezug auf die regulären Ausdrücke für sed: das n-fache Vorkommen eines Ausdrucks. Auch für dieses Thema verwenden wir wieder eine Beispieldatei wh (Wiederholung) mit folgendem Inhalt:
Ktze Katze Kaatze Katatze Katatatze
Listing 4.15 wh
Einzelzeichen
Das mehrmalige Vorkommen von Einzelzeichen kann durch den Stern-Operator (*), den wir Ihnen bereits vorgestellt haben, festgestellt werden. Er kann in einen regulären Ausdruck eingebaut werden und bezieht sich auf das ihm vorangestellte Zeichen. Dabei kann das Zeichen keinmal, einmal oder beliebig oft vorkommen.
$ sed -n '/Ka*tze/p' wh Ktze Katze Kaatze $ sed -n '/Kaa*tze/p' wh Katze Kaatze
Ganze Ausdrücke
Es ist nicht nur möglich einzelne Zeichen, sondern auch ganze Ausdrücke beliebig oft vorkommen zu lassen.
Dabei wird der jeweilige Ausdruck in Klammern geschrieben (die escapet werden müssen).
$ sed -n '/\(at\)*/p' wh
Ktze
Katze
Kaatze
Katatze
KatatatzeListing 4.16 ()
n Vorkommen
Möchte man hingegen die Anzahl von Vorkommen eines Zeichens oder eines Ausdrucks festlegen, so muss man diese Anzahl in (ebenfalls escapte) geschweifte Klammern hinter den jeweiligen Ausdruck schreiben.
Im nächsten Listing muss der Ausdruck at zweimal hintereinander vorkommen:
$ sed -n '/\(at\)\{2\}/p' wh
Katatze
KatatatzeListing 4.17 {}

 Jetzt bestellen
Jetzt bestellen





